DB설계 정리
기말 정리
너무 왔다 갔다 해서 뭘 배웠는지 기억도 잘 안난다
Chapter 1~3까지 SQL 문 개념 + 집계함수와 중첩질의가 함께 사용되는 SQL문 부터(1~7주차)
Chapter 6 : Database Design Using the E-R Model (9 ~ 12주차)
Chapter 7 : Normalization(12~13 주차)
Chapter 4 : Intermediate SQL(14 ~15주차)
Chapter 5 : Advanced SQL (Functions and Procedures 부터) (15주차) 까지
중간 때 수기 정리








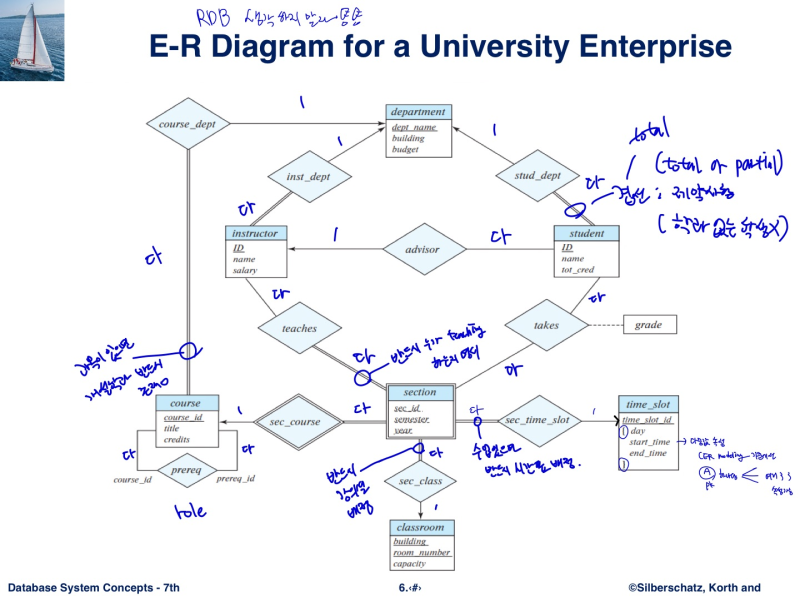
Chapter 6 : Database Design Using the E-R Model
- requirement analysis --> conceptual modeling(ER Modeling)
- 바로 RDB 스키마 만들기 힘드니, abstract한 중간단계를 생성하는 것
- 다양한 설계가 가능하지만, 피해야 할 것들이 존재
--> Redundancy / ex> course 없애면 section에서 여러번 개설 됐을 시 중복
--> incompleteness / ex> course 없애면 개설 되어야만 표시됨 -> pk라 null 값 처리도 불가능
- Entity : 다른 것들과 구별이 되는 개체
- Relationship : entity 간의 관계
==> Entity - Relationship Diagram : ERD
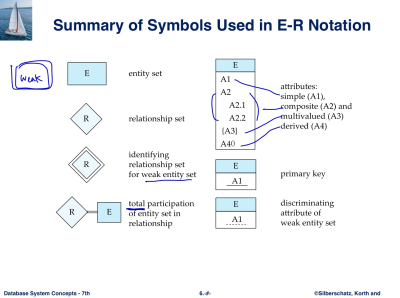
- entity sets - a set of attributes
- relationship sets - entity 사이의 선들을 모은 집합
--> relationship도 따로 attributes 가질 수 있음
--> Role : unary relationship / ex) prereq
--> Degree : n-ary relationship 가능
- attributes
--> single/composite type : name / name-first,second,last(여러 계층 가능)
--> single-value/multivalued : 하나 or 다중값 속성
--> Derived : age (given date of birth)

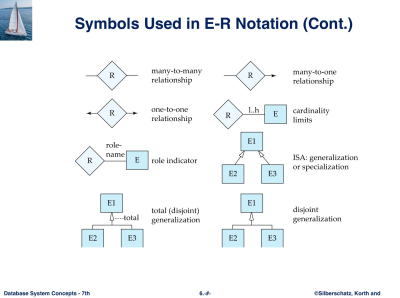
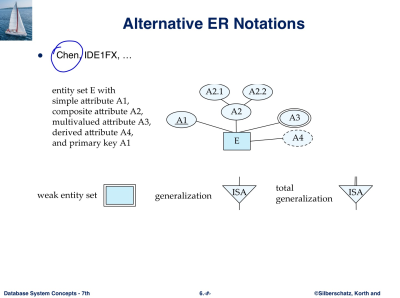
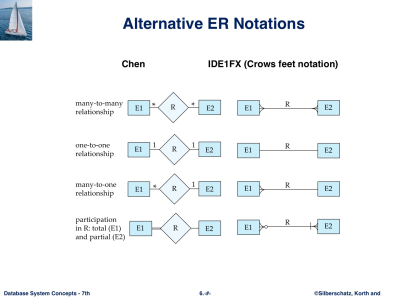
표기법
chen의 표기법은 mutivalued 동그라미 두개
derived - 점선
Mapping Cardinality Constraints
- One to One
- One to Many / Many to One
- Many to Many
- one : 화살표 / many : 걍 작대기
**> ternary 일 때 1:다:다 면 -> A :(B,C) , B:(A,C), C:(A,B) 이렇게 unique 관계가 다 성립
Total and Partial Participation
- total : 모든 entity가 관계에 다 참여해야 함 : 두 줄 relation 표기
- patial : 다 안나와도 되는거 : 한 줄 relation 표기
Notation for Expressing More Complex Constraints
- I..h
- I -> minimum / h -> maximum cardinality
- ex) 0..* : 최소 0개~무한개 / 1..1 : 최소 1개 최대 1개
--> minimum value가 1 -> total participation
Primary Key for Relationship sets
- Binary
--> 다 : 다 -> 둘이 합쳐서 PK됨
--> 1:다 -> 다 쪽이 PK
--> 1:1 -> 어느쪽을 골라도 상관x
Weak Entity Sets : 겹선으로 표시, column은 점선 밑줄
- PK : strong의 PK + weak의 discriminator
- 실세계에서 판단했을 때 독자적인 PK가 있으면 strong으로.
- weak의 weak 가능
- + entity 두개 간의 복수 relationship 가능
교재 연습문제 6.1, 6.2, 6.3
Reduction to Relation Schemas
- composite attributes : 내용물만 취함
- 다중값 속성 : 별도 테이블로 만들기
- derived : 생략
Rdundancy of Schemas
- 다 : 다 -> 독립 테이블
- 1 : 다 -> 다 쪽에 1 쪽 PK를 column으로 추가 후 외래키 처리
- 1 : 1 -> 1:다 와 비슷 but 어느쪽에 추가해도 상관 x
** 만약에 다 쪽이 partial이면, column 추가 시, null 값 많이 발생할 수 있음 -> 독립 테이블 만드는게 나을지도
- weak entity set의 relationship은 그냥 무시함
Extended E-R features
Specialization - attribute & relation 다 상속
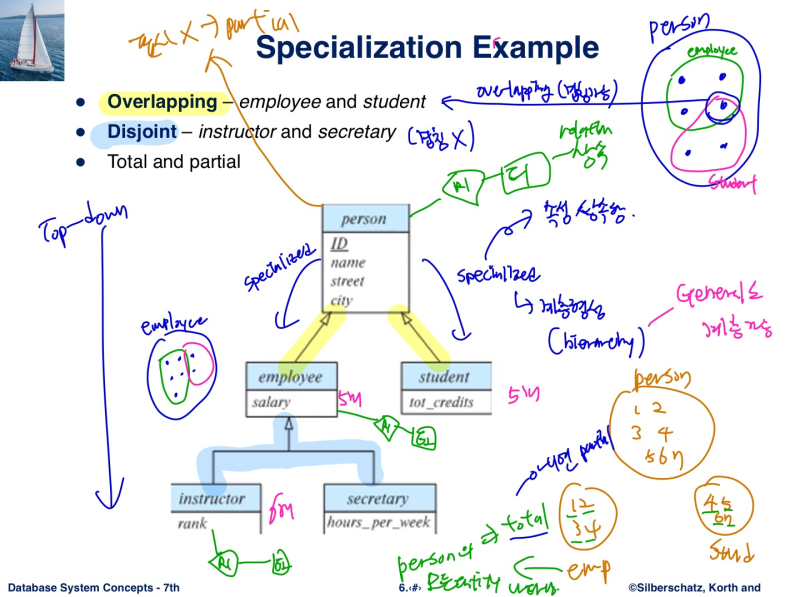
충격 내 필기를 내가 못알아보겠음
단점 : Drawback : 조인을 요구해서 cost가 높아진다
Generalization
- bottom - up
- partial이 default, total이면 표기해줌
Aggregation
- 요소 개념들을 모아서 더 큰 개념 만든다
- binary로 만들어서 표현
Entities vs Relationship sets
- use of entity sets vs relationship sets
- placement of relationship attributes
--> 테이블 변환은.. 너무 많아서 그냥 정리 안함 과제할 때 다 했자나 ㅋㅋ
표기법
Chapter 7: Nomarlization
Features of Good Relational Designs
- insertion anomaly
--> PK가 null이 될 가능성 존재, data가 있는데 DB에 삽입 못 하게 될 수도 있음
- deletion anomaly
--> 삭제할 때 원하지 않는 정보도 같이 삭제 될 수 있음
- update anomaly
--> 하나 업데이트 할 때마다 연관되어 있는 모든걸 다 같이 업데이트 해야함
=> decompositoin을 통해 정규화를 해야 한다.
Decomposition
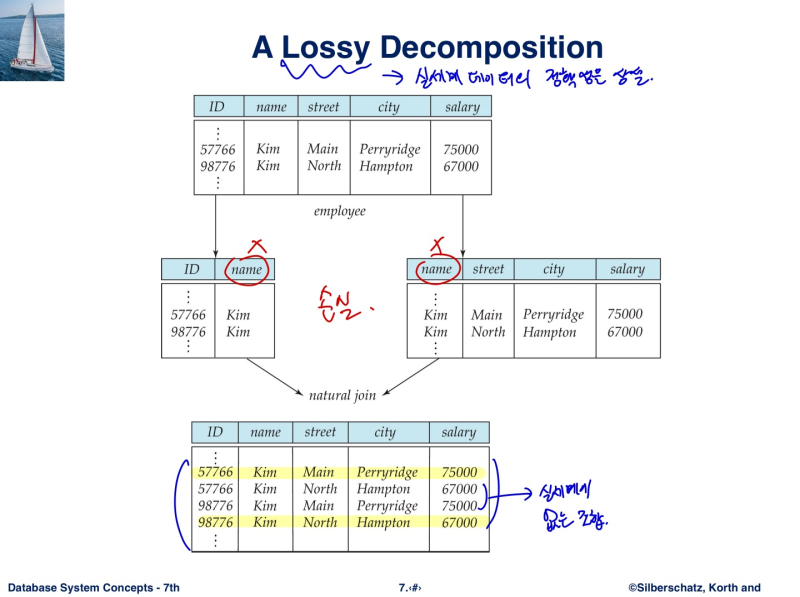
- 분해 시, 다시 조인 했을 때 원래 table로 돌아갈 수 있어야 함
- 근데 맘대로 분해하면, lossy decomposition이 됨
--> 실세계 데이터의 정확성을 상실한다는 뜻
Normalization Theory
- BCNF를 충족할 때까지 decomposition을 함
- Functional dependencies에 의해 분해
Functional Dependencies
- legal instance : 실세계의 제약사항이 다 반영된 tuple들
--> 함수적 결정이 가능해야 한다
α : 결정자
β : 종속자
Closure of a Set of FD ( F+ 를 이 닫힌 F로 계산할 수 있음) -- Amstrong's axioms
- Reflexive rule : B<=A 면, A->B
- Augmentation rule : A->B 면, AC -> BC
- Transitivity rule : A->B, B->C 면, A->C
- Union rule : A->B, A->C 면, A->BC
- Decomposition rule : A->BC 면, A->B, A->C
- Pseudotransitivity rule : A->B, BC->D 면, AC -> D
- sound : 실제로 적용된 FD만을 생성
- complete : 반복 적용 후 모든 FD 생성
Trivial Functional Dependencies
- 당연히 함수 종속 되는 거 ( A->B는 B <= A 일 때 trivial)
- A->A (자기자신) 이거나, {A,B,C...} -> {A} (RHS가 LHS에 속해 있을 때)
Lossless Decomposition
- 분해 했을 때 손실 없는거
- 둘 중에 하나라도 성립하면 무손실 분해
- 무슨 의미냐면, R이라는 테이블을 R1, R2로 분해 했을 때, R1과 R2의 교집합이 R1의 후보키가 되거나, R2의 후보키가 되면, 무손실 분해를 할 수 있다는 뜻

- 1번 예시에서 R1과 R2의 교집합이 B인데, B->BC 라는 조건이 주어졌고, 이는 B->B, B->C로 분해할 수 있음
- 근데 R2 = (B,C)니까 B->BC 라는 뜻은 B->R2 라는 말이고, 이건 B가 R2의 후보키라는 뜻임
- 결과적으로 R1과 R2의 교집합이 R2의 후보키이기 때문에, 이는 무손실 분해
Boyce-Codd Normal Form
- BCNF를 충족하는 정규화 조건
- BCNF인지 아닌지 판단
- 위를 판단하기 위해 non-trivial한 FD와 super key를 알아야 한다.
--> non-trivial한 FD에서 결정자가 super key가 아니라면 이는 BCNF를 위반
** 보통 binary에서 다 : 다로 독립 테이블 만들 시 non-trivial 없음,
** 1:다 에서 column 추가할 때 발생 --> 근데 이 경우는 보통 non-trivial FD가 super key임
** 결과적으로 RDB 잘 만들었으면 ternary 이상 스키마가 아니면 BCNF 대체로 만족하는 듯
ex) 대출정보(R)(고객ID,지점명,대출번호)
- 고객, 지점, 대출의 ternary relationship, superkey는 셋의 PK의 합성
- 대출번호(A) -> 지점명(B) FD가 존재하는데, 대출번호는 super key x
- 실세계에서 공동명의대출이 가능한 상태 :: 고객 여러명이서 지점명, 대출번호 중복됨
--> 대출 정보 테이블 분해 : <A,B>가 한 테이블 :: 대출지점(대출번호, 지점명)
--> R - B 가 한 테이블 :: 대출고객(고객 ID, 대출번호)
(문제가 되는 FD를 독립 테이블로 빼고, 원래 테이블에서 종속자 쪽을 없애서 만든다)
정규형(Normal Form)
- 1NF
--> 각 tuple의 attribute가 atomic value (한 칸에 정보 하나씩만)
- 2NF
--> 1NF 이면서, 모든 속성이 PK에 fully dependency인 정규형
- 3NF
--> 2NF 이면서, PK의 transitively dependent를 제거한 정규형
(table 내에서 PK가 아닌 속성이 결정자가 되는 것을 제한함)
- BCNF
--> 모든 결정자가 항상 후보키가 되도록 테이블을 분해
Chapter 4: Intermediate SQL
Joined Relations
- Natural join
- (Inner) join
- Outer join
Natural join in SQL
- (1), (2)는 equivalent
- natural (left/right/full)outer join
--> 왼쪽에 있는 결과를 다 가져오고, 오른쪽에 있는거 매칭
--> 만약 오른쪽에 데이터가 없으면 null로 표시
--> full은 일단 nutural 조인 후, 양 쪽 없는 데이터 전부 null처리
** mysql에서는 full 지원 x --> left, right 결과 union 해야함
** mysql에서는 from 절 subquery 만든 후 반드시 alias 붙여줘야함
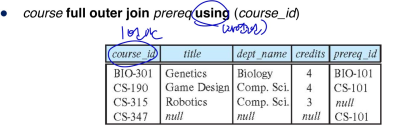
Danger in Natural join
--> 의도는 student와 takes의 ID, takes와 course의 course_id를 join하는 거였지만, incorrect version처럼 sql문을 작성하면, studetn와 course의 department column까지 join 되어 버린다.
--> using 키워드를 사용해서 조인에 사용할 column을 지정해줌
--> using을 쓰면 자동으로 그 column에 대한 자연조인 해줌
--> on 키워드는, 뒤에 아무조건이나 와도 됨 (꼭 자연조인 일 필요x)
using vs on
- (1) using은 course_id가 result set에 1번만 나와야함 (자연조인이라)
- (2) on은 course_id가 result set에 2번 나와야함(course, prereq)
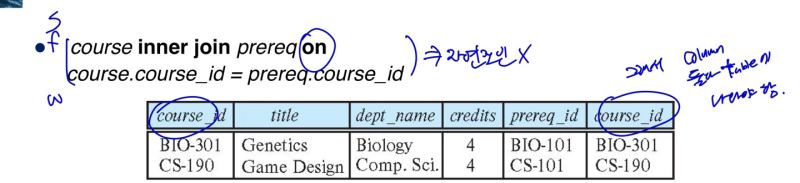
정리

Views
- 사용자가 전체 logical model을 알 필요가 없을 때, 가상 테이블을 만들어서 그것만 visible하게 제공
--> 이 virtual relation이 DB에 저장되지는 않음
View Definition and Use
- salary 같은 민감한 정보를 제외한 교수의 정보를 user에게 제공
- view 이름과 함께 내부 column도 지정 가능
View Defined Using Other Views
- view + view 조합, view+ table 조합, 다 만들 수 있음
- 첫번째 view로 2023 가을학기에 CSE에서 열린 수업의 building 정보 열람
- 두번째 view로 특정 building의 room_number 열람
Integrity Constraints
- not null - null 값 못 넣게 제약
- primary key - 자동 not null 처리
- unique - null 값 허용 되는 candidate key를 명시
- check(P), where P is a predicate
--> check 절에 있는 문장대로, semester에는 저 4개의 값들만 허용
--> time slot에 없는거 section에 추가 불가, section에서 쓰는거 time slot에서 삭제 불가
Referntial Integrity(참조 무결성)
- 참조 대상 쪽에 값이 반드시 있어야함
--> foreign key 제약 : 값이 반드시 있어야 하고 + 참조 당하는 column이 PK 여야함
Cascading Actions in referential Integrity
- department에서 뭔가 삭제되면, 참조하던 course 에서도 tuple 같이 삭제
- department에서 뭔가 변경되면 , 참조하던 course에서도 같이 변경
- cascade 대신 쓸 수 있는 두가지
- set null : 삭제/변경 하는 것이 아닌 참조하던 값만 null로 변경
- set default : 삭제/변경 하는 것이 아닌 참조 값을 default 값으로 변경
- restrict : 해당 연산을 아예 금지 시킴(뭔가 바뀌는 것) :: 이게 default
Assertion
(mySQL에서 지원 안한다..)
- student의 tot_cred는, student가 들은 course의 credits의 합이어야 함.
- 제약 조건이 위배되는 연산을 수행하지 못하게 함
- coalesce(arg1, arg2... , 0) : arg 값이 null이면 0 return, 아니면 그 값 그대로
- 학생이 들은 학점을 다 합친게, 학생 테이블의 tot_cred이랑 같지 않은게 없으면, True return
--> exists랑 = 을 쓰면, 학생들 중 옳게 된게 하나라도 있으면 True가 나와서 잘못된걸 거르지 못함
Built-in Data Types in SQL
- date '2023-7-11'
- time '09:00:30'
- timestamp '2023-7-11 09:00:30.75'
- interval '1' day (위의 연산들 더하고 빼서 나온 값들)
Large-Object types (LOB)
- blob : binary large object
- clob : character large object
--> 너무 커서 반환할 때 itself 보다는 pointer 활용
User-Defined types
user defined Domains
- domain은 constraints를 가질 수 있음
Authorization
- Read, Insert, Update, Delete
- grant 할 수 있음
- <privilege list>
- select
- insert
- update
- delete
- all privileges
- <user list>
- a user-id
- public
- a role
Revoking Authorization in SQL
- privilege list가 all 이면 모든게 다 회수됨
- revokee list가 public이면 모든 사용자가 권한 회수
- 만약 어떤 사용자가 권한을 두번 받으면, 한쪽에서 회수 해도 남은 한쪽에 의해 권한 존재
** with grant option
- 권한 부여할 때, 남한테 권한을 부여할 수 있는 권한도 줌
--> revoke 시 cascade면, 앞에서 권한 없어지면 걔한테 받은 애들 것도 다 같이 회수
--> restrict면, revoke 연산 자체를 반려함(만약 회수 대상자가 아무한테도 안나눠줬다면 그 당사자 것만 회수)
Roles
- role이 privilege 인 것 처럼 사용
- role 과 role간의 grant 가능 (inherits)
chapter 5: Advanced SQL
Declaring SQL Functions
- 내장되어 있어서 사용할 때 굳이 조인 안해도 되는 장점이 있다.
Table Functions
- 그냥 해도 되는데 굳이? 싶지만...... 미리 정의 해두면 가독성 면에서 좋을거 같긴함
SQL Procedures
- call 해서 사용할 수 있음
Functions and Procedures
- data 뿐만 아니라, 그 data를 위한 연산들도 사용자가 정의해서 저장할 수 있음
Triggers
- 삽입/삭제/업데이트 시 trigger를 설정해서 자동으로 DBMS가 DB를 수정해줌
- 학점 변경 시 tot_cred 자동 업데이트 시스템
- before 설정을 null로 해줘야 위에서 null 값 인식 후 변경 가능