Code generator
intermediate representation을 machine level code로 변환하는 과정.
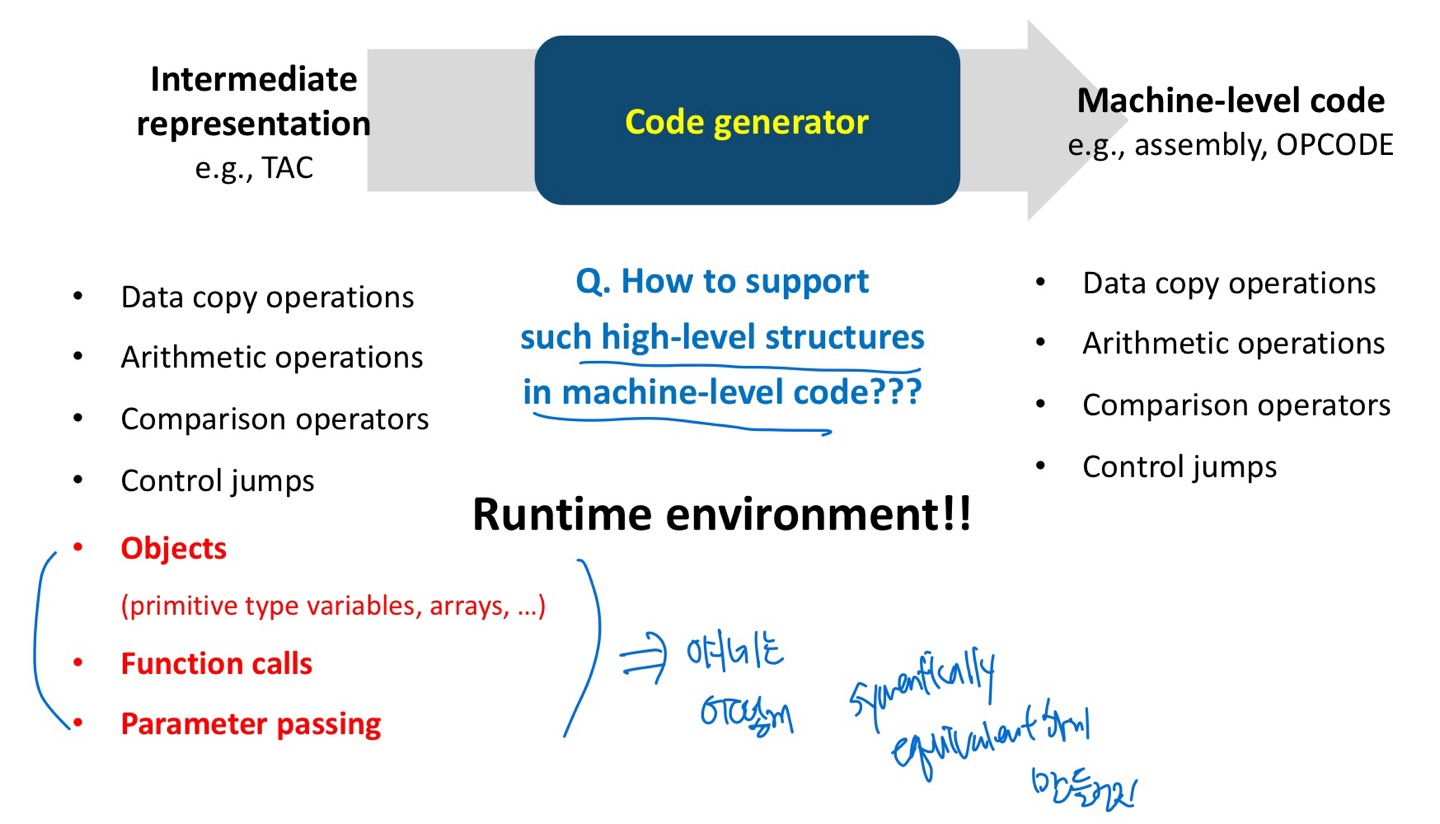
=> machine level로 표현하기 힘든 structure들은 어떻게 표현해야 할까?
Runtime environment
high level structure를 지원하기위해 run time에 사용되는 set of data structures
여러 이슈를 다룸
- What do objects look like in memory?
- What do functions look like in memory?
- Where in memory should objects and functions be placed?
Object representations
Data alignment
=> 컴파일러가 object가 memory에 어떻게 배치되고 접근되는지 결정한다.
=> N-byte alignment : object 들의 시작 memory가 해당 object type size(N)의 배수로 결정됨

=> 이런 memory 시작 점들을 compiler가 compile time에 결정한다
=> padding : 중간에 비는 공간에 가능한 type들을 끼워 넣을 수 있다(?)
Representing arrays
=> C - style : index 0부터 n-1까지 연속적으로
=> java - style : 맨 앞에 size 크기 적고, 그 뒤로 연속적으로
Representing multi-dimensional arrays
=> C -style : 걍 연속으로 쭉쭊쭊...
=> java - style => linked list
Function representations
1) function 간의 call 같은 relationship을 어떻게 표현?
2) function에서 쓰이는 infor들을 어떻게 관리? (parameter, return value..)
Activations
function F를 호출(invocation) 하는 것은, F의 activation을 부르는 것과 같다.
=> activation의 life time은 해당 F의 모든 statement가 실행될 때까지.
=> 만약 F가 다른 function Q를 불렀으면 F의 activation은 Q가 종료될 때까지를 포함한다.
=> function 간의 relationship은 activation tree로 표현한다.

해당 tree는 stack을 이용해서 관리한다.
So,
How to represent the relationship betwwen functions?
=> use a stack
Activation records
=> function F의 activation을 관리하는데 필요한 정보들
1) input parameters
2) space for F's return value
3) control link : F를 call한 caller function의 AR 주소를 point
4) machine status prior to calling F (return address, contents of registers)
5) F's loval, temporary variables
==> 해당 함수가 불리면, 해당 함수의 activation record가 stack에 push 된다.
==> 끝나면 pop
So,
How to keep the information needed to manage functions?
=> store an activation record
Memory layout
=> 컴파일러가 code와 data를 memory에 어떻게 저장할건지 결정함
global variable : static하게 저장되어야 함
activation record : stack에서 관리, 위에서 아래로 내려온다
dynamically allocated data : heap에서 관리, 아래에서 위로, AR과 다르게 프로그래머가 선언-free 할 때까지가 life time
So,
어떻게 high level structure를 machine level code에서 지원하냐?
=> Runtime environment를 이용
=> 자 이제 진짜 바꿔보자
MIPS assembly
(우리 class에서는)
=> 32-bit machine architecture ( 1 word = 4 byte = 32 bit )
=> 모든 object는 전부 동일하게 4-byte aligned로 가정.
=> 두종류의 register만 있음 $sp, $r0 ~
=> $r0 ~ infinite => register 무한하다고 가정
=> intermediate representations은 직접 assembly로 변환한다고 가정
=> basic instruction



AR이 구조화 돼서 이미 존재, 이걸 run time에 해당 function이 불리기전에 프로그램이 stack에 넣어줌.
걍 쭉쭉 진행...

Return value (아직 empty space)
a = 3 (parameter)
control link ( caller func의 AR 시작 주소 )
return addr => $ra 사용 (special register) => foo 끝나고 다음에 실행해야 할 코드 찾기
space for t0 (foo에서 사용하는 local var 저장할 공간 만들고)
t0 = 4 (계산 후 담고)
return value = 4 (t0 가 return 값이니 같이 넣어줌)
이후 &ra에 return address에 담긴 주소를 넣어줌
그리고 stack에서 control link 만큼 $sp를 땡겨서, 남은거 pop
$ra가 가리키는 위치로 jump
어셈 문법은 해봐야 알듯
근데?! 이건 register가 무한이라고 가정했을 때 얘기고, 현실은 그렇지 않음.
==> register 사용을 최소화 해야함
Better register allocation
=> live variable 컨셉을 이용해서 register 재사용
=> a와 b가 같은 point에서 live variable이 아니라면, a와 b는 같은 register를 사용해도 무방함.
Register allocation with live variable analysis
1) live variable을 globally하게 실행
2) Register Interference Graph (RIG)를 만든다

=> 각 변수를 node로 만들고, 같은 시점에 같이 live 면 edge 생성
==> edge가 없으면 reg 공유 가능
Graph coloring
NP-hard problem => heuristics
하는 법
1) K 개보다 edge가 적은 node를 edge와 함께 제거함
2) 제거한 node를 stack에 push
3) RIG에 node가 남아있지 않을 때까지 위에 반복
---
4) 이후 stack에 들어간 node를 pop하며 reconstruct
5) node를 꺼낼 때, 색(reg) 을 하나씩 지정해줌 => edge 있는 node끼리는 다른 색으로
6) 다 복원하면 k-colorable 성공
만약 도중에 k 개보다 edge가 적은 node가 존재하지 않는다면 fail
==> 이걸 해결할 방법이 있는데 그게 바로 spilling
아까 k개보다 edge가 적은 node가 존재하지않는 RIG 상황에서, spilling할 node를 하나 골라줌.
=> 이 선택된 node는 reg를 사용하지 않고 그냥 memory에서 쓴다고 생각하는거

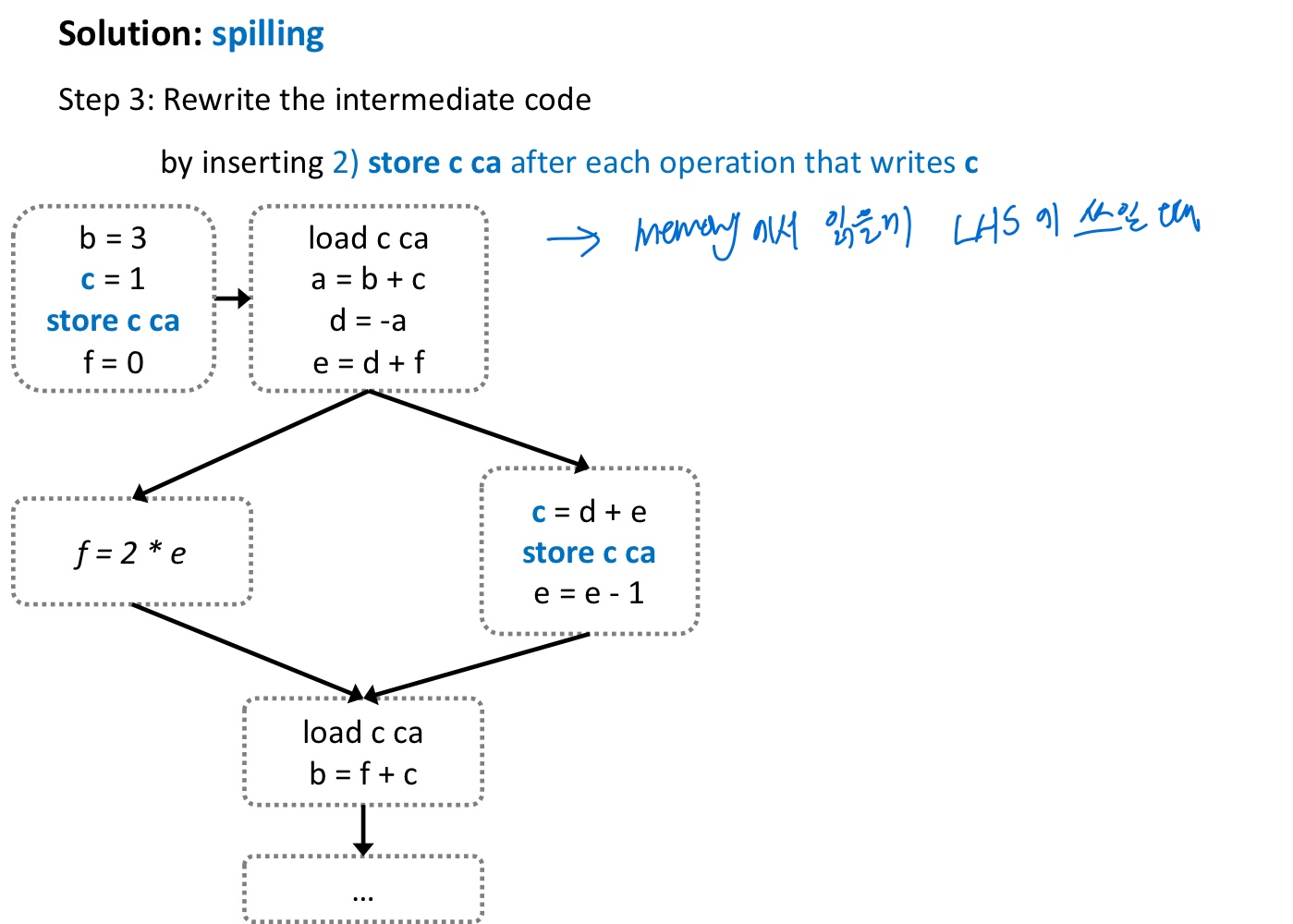
load, store를 그냥 다 진행해주고


그걸 해당 그 부분에서만 쓰는 변수로 renaming을 해줌
그리고 다시 graph coloring 해준다
=> 그렇지만 spilling할 변수를 잘못고르면............
=> 될 때까지 계속 해야함.
=> spill할 node를 고를 때, 어떤걸 골라야 하는지에 대한 정답은 x
=> 뭐 상황에 따라 edge가 가장 많은걸 고른다거나, 자주 쓰이는걸 고른다거나...