
수정입니다
Memory Hierarchy(4) - virtual memory 본문
Problems
- 두개의 프로그램이 동시에 하나의 메모리를 사용하고 싶음
--> 만약 그렇게 한다면, 이 하나의 main memory를 공유하고싶음
(하나의 프로그램에서 두개의 instance를 돌리는 것도 비슷한 문제)
- 프로그램 A는 2GB memory가 필요한데, 내 컴퓨터는 1GB뿐임
- memory size를 알 필요 없이 software를 쓰고 싶음
Virtual Memory
- main memory를 2차 저장장치인 disk의 "cache"로써 사용한다
--> 여러 프로그램들이 효율적이고 안전하게 메모리를 공유하기 위해
--> 작고 제한적인 main memory에서 프로그래밍 하는 부담을 줄이기 위해
--> CPU hardware 와 operating system(OS)이 같이 관리함
- program share main memory
--> 각 프로그램이 private 한 virtual address space를 얻고 거기에 자주 쓰는 code와 data 저장
--> virtual address space가 physical address로 변환된다
--> OS가 다른 프로그램으로부터 보호해줌
- 하나의 프로그램이 기존 메모리 사이즈를 초과해서 사용하는걸 허용해줌(느리긴 함..)
--> virtual memory가 자동적으로 two level로 계층 관리를 해줌 (main, disk)
- CPU와 OS가 virtual -> physical로 변환해줌
--> virtual memory block == page
--> virtual memory translation miss == page fault : 매~우 느림
--> disk 가 느리기 때문에, software에서 더 좋은 알고리즘을 사용해야함 (OS 에서 handled)
- Relocation
--> address가 사용되기 전에, physical memory의 다른 장소에 먼저 위치시켜놓음
--> 그리고 그걸 main memory의 아무 곳에나 loading 시킴(연속적인 위치가 아니어도 됨)
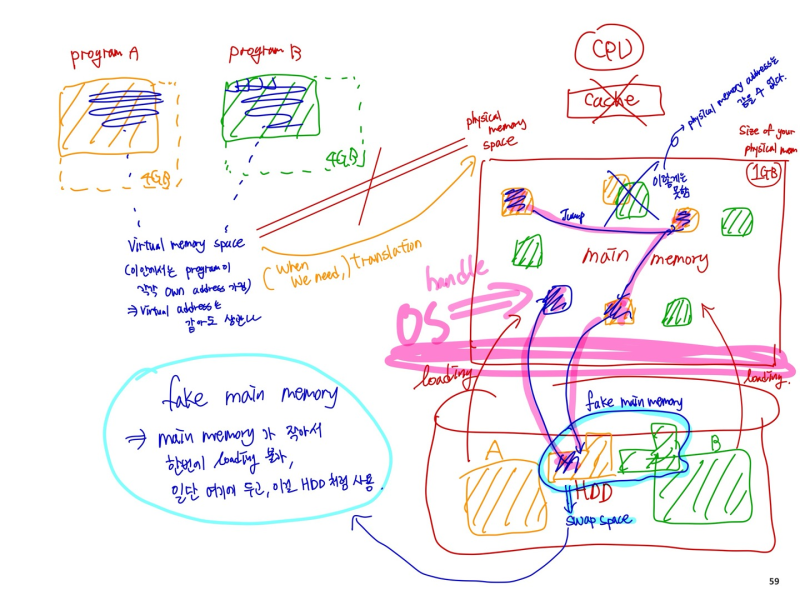
--> 내 프로그램은 virtual memory address를 run함 그러면 translation이 발생한다
Address Translation
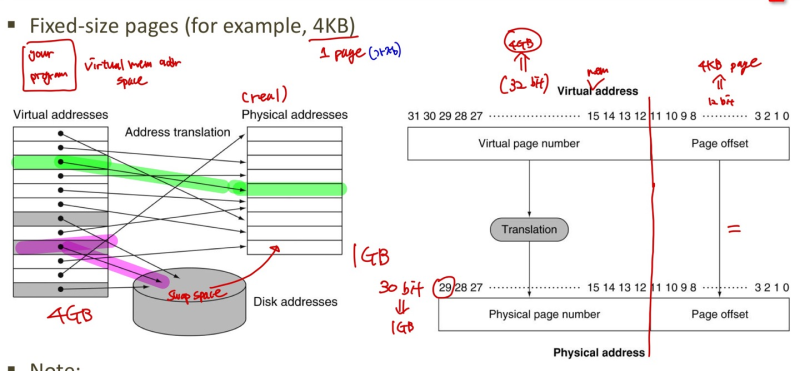
--> 1page = 4KB 가정 (한 번에 HDD에서 copy 할 수 있는 양)
==> 22*210 = 12 bits Page offset
--> virtual address size : 4GB 가정 = 22*230 = 32bits
--> physical address size : 1GB 가정 = 1*230 = 30bits
==> virtual space가 physical space보다 크다고 가정한 것
Page Table
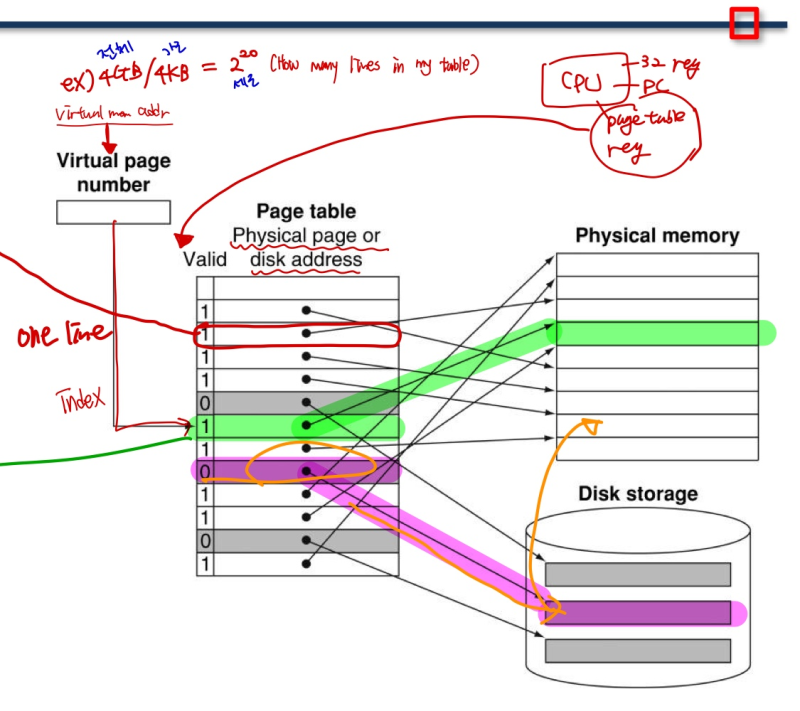
- translation을 하면 page table이 생김
--> page table entries(PTE) : page table의 one line에 접근하기 위한 index 번호
(전체 virtual space / page 당 크기 == 각 line의 개수)
--> page table register in CPU : 각 프로그램의 page table 위치를 가리킴 ( 1개 )
--> page table 은 per process 라 각 프로그램마다 main에 page table을 가지고 있음
=> page table reg 하나를 OS가 매우 빠르게 switching 해줌(context switching)
- page가 memory에 존재 하면
--> page table entry가 physical page number를 저장하고 있음. 가면 됨
- page가 memory에 존재하지 않으면
--> page table entry가 disk의 swap space 위치를 알려줌. 들렸다가 가면됨.
Translation Using a Page Table
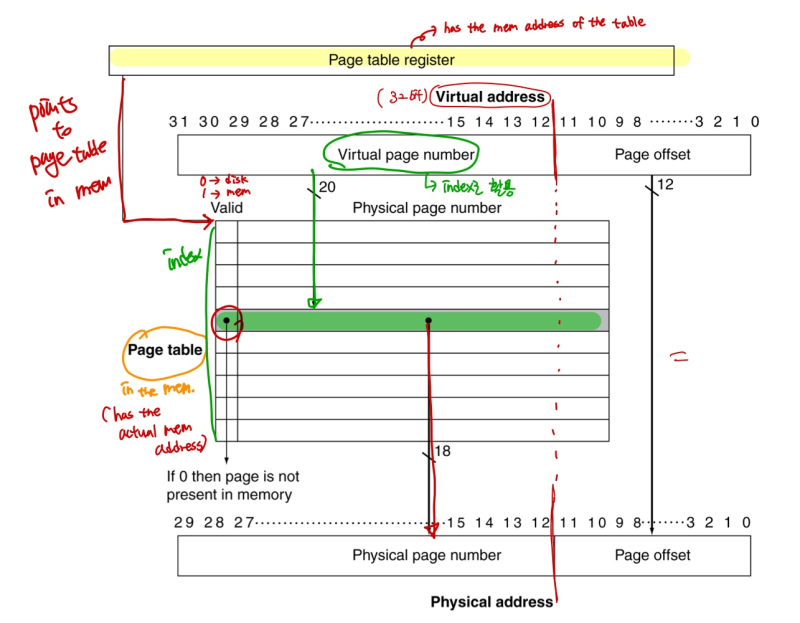
Replacement and Writes
- To reduce page fault rate, prefer least-recently used (LRU) replacement
--> 주기적으로 reference bit = 0인거 치움 (최근에 안쓴거라)
- Disk write take millions of cycles
--> write through 너무 느림, Use write-back
--> Dirty bit in PTE set when page is written
Fast Translation Using a TLB
- Translation look-aside Buffer(TLB) - page table을 위한 special cache
--> a fast cache of PTEs within the CPU
--> virtual memory가 실행됐을 때, 1. page tabel에 가고 2. 실제 그 주소 찾아가는것 보다, TLB로 바로 간다
** memory cache랑 TLB는 almost independent 하다.
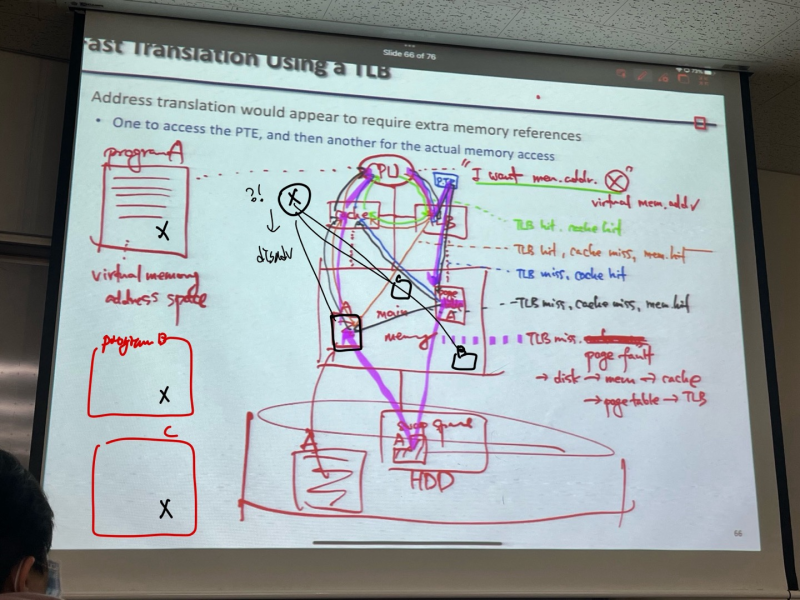
1. TLB hit, cache hit
2. TLB hit, cache miss -> go to momory ->memory hit
3. TLB miss -> go to page table -> cache hit.
4. TLB miss -> go to page table -> cache miss -> go to memory -> memory hit
5. TLB miss page fault -> disk -> mem -> cache -> page table -> TLB
** TLB에서 virtual addr 로부터 physical addr를 얻음. 근데 이 실제 주소가 cache에 있을수도 있고 없을 수도 있고, 메인 메모리에 올라가 있을수도 있고 없을 수도 있음 (왜냐면 메인 메모리는 하드디스크에서 조금씩 가져온다고 했다.)
TLB Misses
- page가 memory에는 존재하는데, PTE가 TLB에 없는 경우
--> PTE를 mem에서 TLB로 복사 후, 명령 재실행
--> could be handled hardware or software
- page가 memory에 올라오지 않은 경우(page fault)
--> OS 가 page를 memory에 fetch 하고 page table update
=> fetch 할 PTE 찾고, disk에서 page 위치 찾음, dirty한 page 먼저 replace, 이후 memory에 올리고 page table에 올림
--> 이후 명령 재실행
TLB and Cache Interaction
- 만약에 cache가 physical addr를 사용하면
--> virtual 을 translate 하고 나서 cache로 보내야 됨. TLB hit일 때는 괜찮은데, TLB에서 miss나면, main에 있는 page table로 가서 physical addr 로 바꾸고 나서 cache로 와야함 --> 느려...
- Alternative : use virtual address tag
--> virtual address를 TLB 거쳐서 translate 하지 않고 cache에 바로 줘버림
--> ssssssuper fast BUT complications due to aliasing
--> virtual은 프로그램마다 각자 쓰고 겹쳐도 되는거라서, 이게 main mem으로 들어오면 같은 virtual addr인데 어떤 physical addr를 가리키는 건지 복잡해짐. ( 위 그림 disadv. 가 이부분)
=> 뭐가 더 나은지는 보장할 수 없다.
Cache Coherence problem
- two CPU cores 인데, one memory인 상황 가정
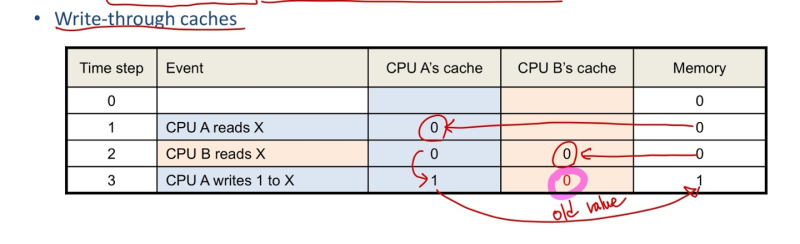
- 가장 간단한 방법 - Invaildating Snooping Protocols
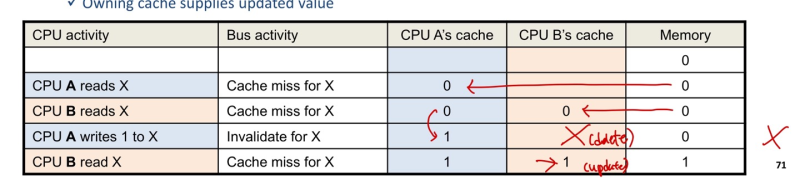
--> 어느 한 코어가 쓰면, 나머지 코어가 전부 가지고 있던 정보를 지움, 이후 새로 업데이트.
Multilevel On - Chip Caches
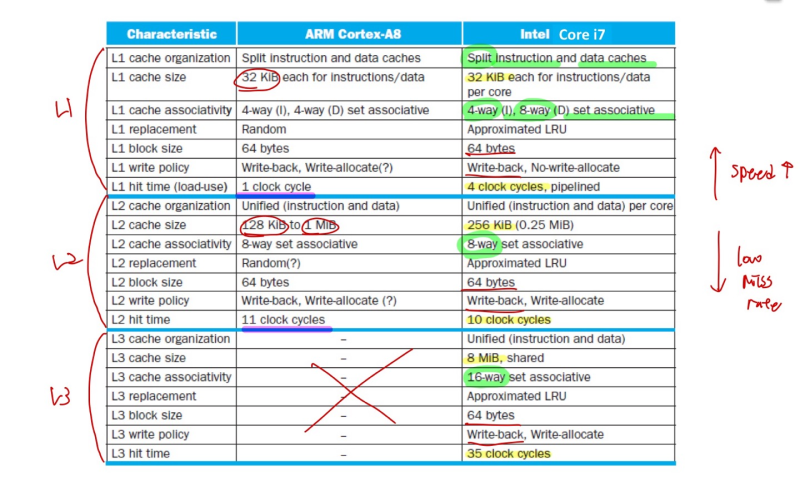
--> 높은 계층의 cache 일수록 속도는 빠르지만, 내려갈 수록 miss rate를 덜 일으킨다.
2-Level TLB Organization
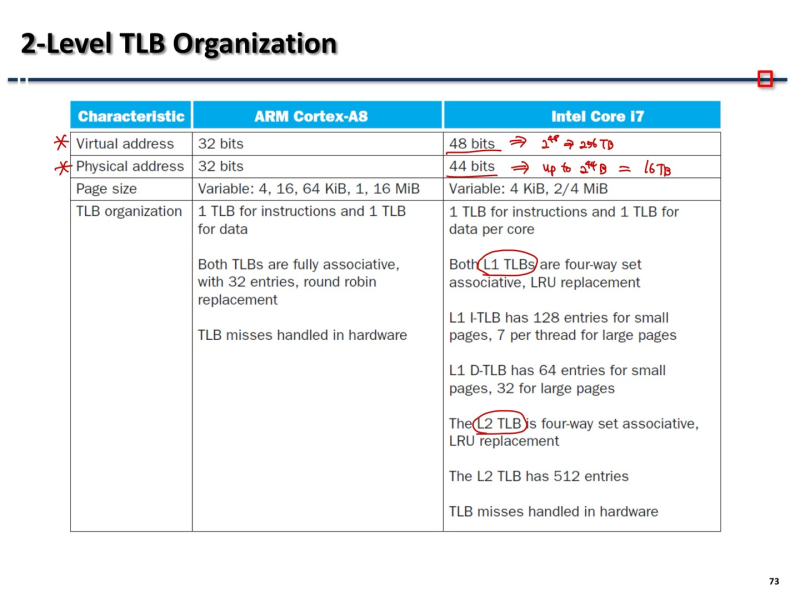
끝@@
'전공 > 컴퓨터구조' 카테고리의 다른 글
| Memory Hierarchy(3) - Cache_2, Hamming code (0) | 2023.12.28 |
|---|---|
| Memory Hierarchy(2) - Cache_1 (0) | 2023.12.28 |
| Memory Hierarchy(1) - Disk access time (0) | 2023.12.28 |
| Pipelining(2) (0) | 2023.12.28 |
| Pipelining(1) (1) | 2023.12.28 |


