
수정입니다
Pipelining(2) 본문
MIPS Pipelined Datapath
IF -> ID -> EX -> MEM -> WB
-> 한 cct에 최대 5개의 stage 실행 가능
만약, IF stage가 current instruction 이라면 ID stage는 previous instruction을 실행하고 있을 것
ex) c1 c2 c3 c4 c5 ( clock cycle time, 세로로 묶었을 때가 현 시점(c2) 실행되는 stage들)
IF ID EX MEM WB - 이전 명령은 같은 cct에서 ID stage를 실행하고 있음.
IF ID EX MEM WB - IF stage가 수행하는 것이 현재 명령이라면,
같은 논리로, 시점을 바꿔서 생각해보면
만약, ID stage가 current instruction이라면 , IF stage는 next instruction을 실행하고 있을 것
ex) c1 c2 c3 c4 c5 ( clock cycle time, 세로로 묶었을 때가 현 시점(c2) 실행되는 stage들)
IF ID EX MEM WB - ID stage가 수행하는 것이 현재 명령dl라면,
IF ID EX MEM WB - 다음 명령은 같은 cct에서 IF stage를 실행하고 있음.
(그림을 그릴 때는, 이해가 쉽게, conceptual 하게, 각 명령들의 stage를 나열하여 표현했지만,
in real, 보여지는건 어떤 한 시점(c2) 에서 어떤 stage들이 돌고 있는(ID, IF) 모습임- 빨간부분만)
Right-to-left flow leads to hazards
- data hazard
ex) prev.prev.prev.prev inst (WB) - > prev inst(ID)
- control hazard
ex) prev.prev inst(EX) - > current inst(IF)
--> In pipelining, one stage must finish at one clock.
(같은 cct에서 돌고 있는 다른 instruction stage의 결과값을 받아서 동일 cct에서 내 inst stage에 사용할 수 없다는 얘기)
(즉, conceptual 한 그림에서, 오른쪽 -> 왼쪽으로 값을 넘겨주는 꼴 == hazard 발생)
Pipeline register (new 4 reg) - 마찬가지로 write 시 왼쪽, read시 오른쪽(그림에 표현 안되어 있다)
- to hold information produced in precious cycle
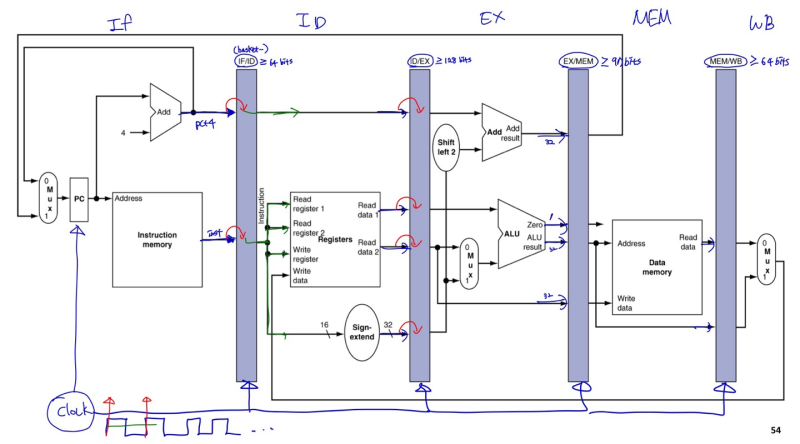
ex) lw instruction (lw에서 쓰이지 않는 정보들(read reg2, zero...등)도 그냥 다 저장되지만, 쓰이는 것만 적어봄)
- IF/ID - PC+4 주소 저장, instruction 정보 저장(lw)
- ID/EX - PC+4, rs, rt, offset(sign extend) register 정보 저장
- EX/MEM - PC+4, ALU result 저장
- MEM/WB - read data 저장
+ PC register
각 reg들은 각각의 파이프라인에 대한 정보를 저장 후, 계속 다음 reg으로 사용할 때까지 계속 넘겨준다.
(안써도 그냥 일단 저장한다. 쓰면 좋고, 안쓰면 버리면 됨)
이후 data에 저장 된 값을, WB stage에서 Reg file로 돌아와 write reg에 data를 넣어줘야 한다.

만약 지금까지 한 lw inst의 WB stage를 current로 본다면 현재 ID stage는 next next next inst가 사용하고 있을 것이다.
그럼 이상한 곳에다 쓰게 되는 거 아니냐?
- IF/ID register가 inst 정보를 저장할 때, lw의 write register number도 계~속 저장해놓고 있음
- lw가 WB stage가 되어 다시 regfile로 돌아왔을 때, 맞는 write reg #도 같이 계속 쭉 정보가 이어져서 제대로 쓸 수 있게 된다.
Multi - Cycle Pipeline Diagram

Single-Cycle Pipeline Diagram

Pipelined Control
- pipeline을 사용하면서 그동안 single로 생각했던 것에서 변화가 생김
- just 쓰는 timing의 변화.
EX : RegDst, ALUOp1, ALUOp2, ALUSrc
MEM : Branch, MemRead, Memwrite
WB : Reg-Write, MemtoReg
single - cycle
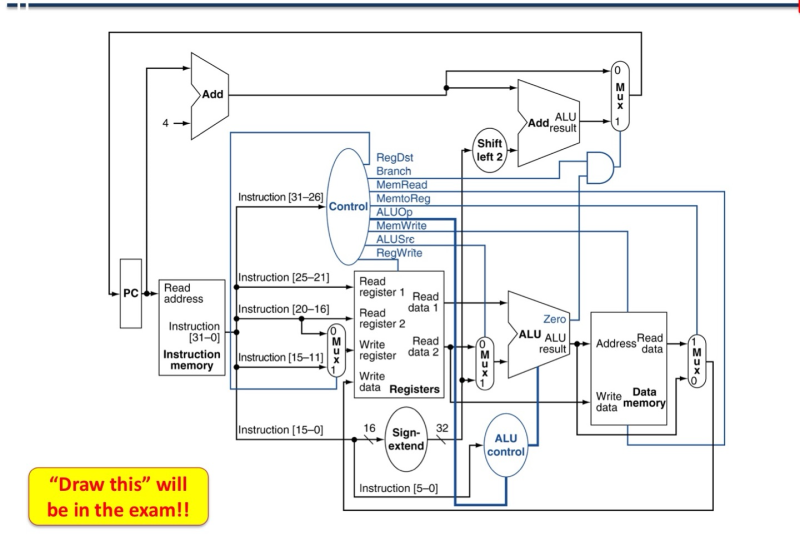
multi - cycle
IF 에서 instruction 정보를 Control에 연결하고, ID/EX에서 모든 정보 저장하고 있다가, 각 필요한 타이밍에 꺼내 쓴다.
사용한 control signal은 더이상 필요없으므로 다음 reg에 stored 하지 않음.
Detecting Data Hazard the Need to Forward
- 앞 포스트인 pipelining(1)에서 봤듯이, 우리는 forwarding을 통해 hazard를 해결할 수 있다
- 그렇다면, How do we detect when to forward?
ex)
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
$2 reg 이용시 두가지 케이스의 hazard 존재
case 1.
sub $2, $1, $3
- rs, rt가 ID/EX reg에 정보가 저장 되고, EX에서 ALU 계산을 한 후 그 정보를 EX/MEM reg에서 rd에 담음
and $12, $2, $5
- rs, rt가 ID/EX 에 저장되고, EX에서 계산해야 되는데, rs인 $2가 위에서 아직 안옴
=> EX/MEM Reg Rd == ID/EX Reg Rs == $2 -> hazard
case 2.
sub $2, $1, $3
- rs, rt가 ID/EX reg에 정보가 저장 되고, EX에서 ALU 계산을 한 후 그 정보를 EX/MEM reg에서 rd에 담음
- 이 사이에 case 1 hazard가 발생하는 것
- MEM/WB reg로 move & stored
or $13, $6, $2
- rs, rt가 ID/EX 에 저장되고, EX에서 계산해야 되는데, rs인 $2가 위에서 아직 안옴
=> MEM/WB Reg Rd == ID/EX Reg Rt == $2 -> hazard
정리하자면
Data hazards when
1a. EX/MEM Reg Rd = ID/EX Reg Rs (위 case 1 )
1b. EX/MEM Reg Rd = ID/EX Reg Rt
2a. MEM/WB Reg Rd = ID/EX Reg Rs
2b. MEM/WB Reg Rd = ID/EX Reg Rt (위 case 2)
- 1 -> current(sub inst) vs next(and inst) , 2-> current(sub inst) vs next.next(or inst)
- Data hazard 는 register에 뭘 쓸 때만 발생한다. (뭐 안쓰면 신경 쓸 필요 없음) --> RegWrite 하냐 안햐냐
(R-type, lw, I-type(non lw/sw)
- Data hazard는 Rd가 zero reg가 아닐 때 발생(zero reg에는 뭘 쓸 수가 없다)
--> 이런 조건일 때 we detect the hazard
Forwarding paths

data hazard 감지하는데 필요한거
- current(rs,rt), prev rd, prev.prev rd, prev Regwrite, prev.prev Regwrite
- Forwarding unit에서 이것들이 같은지, 같지 않은지 판단
판단 후 3가지 control to mux
- no forwarding
- forward from the prev instruction - EX hazard
- forward from the prev.prev instruction - MEM hazard
** lw시 write reg 가 rt인데 그건 따로 다뤄야 함
EX hazard : curr vs prev
MEM hazard : curr vs prev.prev
위에서 말한 조건들로 따져서 forwarding 결정
Double Data Hazard
- Both hazards occur -> want to use the most recent(take the latest value)
- MEM harzards ==> Only forward if EX hazard condition isn't true
ex)
add $s1, $s1, $s2
add $s1, $s1, $s3
add $s1, $s1, $s4
-> take green forwarding, not orange (둘 다 일어나면 가까운 forwarding만 하면 된다)
Load-Use Data Hazard
- need to stall for one cycle
Load-Use Hazard Detection
ex)
lw $2 20($1) - load inst
and $4, $2, $5 - using inst
using inst가 ID stage에서 쓰는 ALU operand reg
-> IF/ID.Reg Rs, IF/ID.Reg Rt
Load-use hazard when
- ID/EX.MemRead 사용
- ID/EX.Reg Rt = IF/ID.Reg Rs
- ID/EX.Reg Rt = IF/ID.Reg Rt
(ID/EX.MemRead signal 확인 -> lw 명령이 있음
- 왜 ID/EX에서 확인할까 생각해 봤는데 MEM stage에서 이걸 쓰기 전에 hazard가 있나 확인해야해서 그런거 같다.
- IF/ID reg를 확인하는 이유도.. 위에가 ID/EX인게 맞다면 바로 next inst는 IF/ID를 하고 있을테니...
ID/EX reg Rt -> lw 명령의 wirte register
IF/ID reg Rs,Rt -> 어떤 명령에서 사용하는 reg들
둘이 같다면, lw 명령에서 write back 할 regi를 next inst에서 바로 사용 => 불가능)
If detectd -> stall and insert bubble
How to Stall the Pipeline - two actions
1. Force control values in ID/EX register to 0
- ID/EX reg에 있는 control signal을 다 0으로 만들어서 instruction을 NOP(no-operation)으로 만든다.
--> 예정 되어있던 EX, MEM, WB stage가 cancle 됨
2. Prevent update of PC and IF/ID register
- PC랑 IF/ID를 update 하지 않으면
- 1. 아까 IF stage에서 하던거 한번 더 함 (curr inst ID stage에서 멈췄으니, next inst 는 IF를 하고 있었겠지)
- + curr inst ID stage에서 하던 것도 한번 더 함
- 1-cycle stall allows MEM to read data for lw
Stall/Bubble in the Pipeline
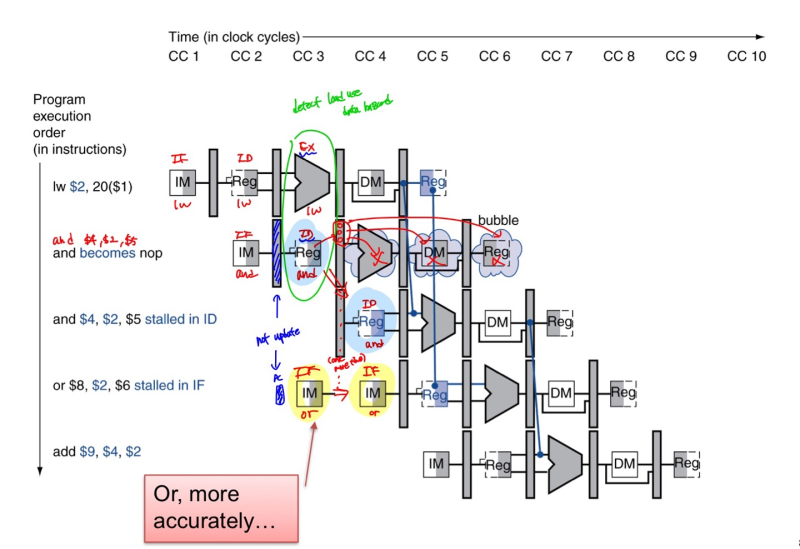
전에도 언급 했던 것 같지만, read는 몹시 빨라서 write/read는 한 cct 내에서 동시에 처리가 가능하다.
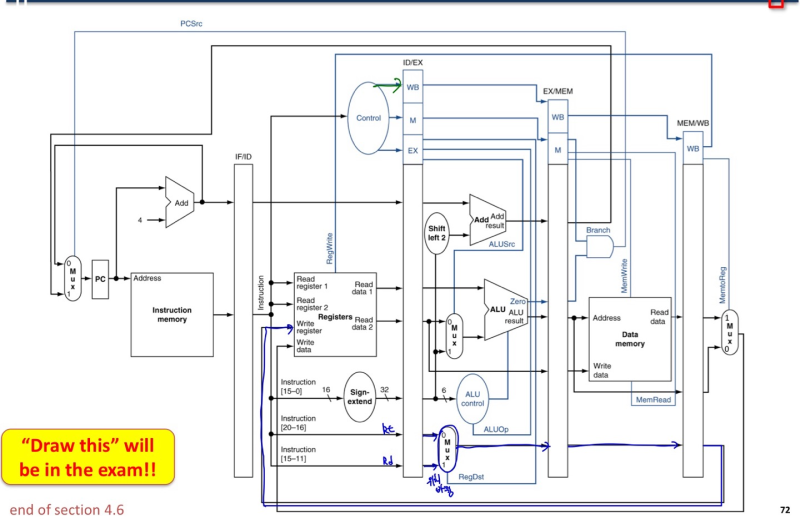
Datapath with Load-Use Hazard Detection

load use hazard 감지하는데 필요한거
- ID/EX.MemRead, ID/EX reg Rt, IF/ID reg Rs, Rt ,
- Hazard detection unit에서 감지하면, stall 진행(control signal 0, PC, IF/ID 0)
Stall and Performance
- Stalls reduce performance -> but get correct results를 위해 요구됨
- Compiler can arrange code to avoid hazards and stalls -> 파이프라인 구조에 대한 지식 필요
(인텔이나 AMD나 각자 자기가 만든 컴파일러 쓰는 이유... )
Instruction - Level Parallelism(ILP) -- performance를 높이기 위해 이걸 높임...
To increase ILP
- Deeper pipeline (stage 당 일을 줄이면, clock cycle이 짧아지고 그만큼 stage가 추가됨. stage 개수만큼 more faster)
--> 물론 각 stage마다 시간이 다르고 각 타임마다 wasting이 있고 그 한계가 분명이 존재하지만 일반적으로 이렇게 말한다
--> 또 한편으로는 stage가 아주 많거나, 길거나 하면 하나의 hazard가 생겼을 때 더 치명적이다 => 밸런스를 맞춰야 함
- Multiple issue (hope twice faster)
--> just created more datapath - some stage를 걍 늘린다는 뜻.. 여러개..
--> run n instruction in same time (hazard가 없으면)
--> stall이나 이런 여러가지 것들이랑의 dependencies 때문에 실질적으로 n배 빨라지거나 그러지 못함
- Loop Unrolling
--> reduces loop-control overhead
--> 복사붙여넣기가 멍청해보이지만.. 사실 그게 loop보다 빠르다(hazard 이슈)
Power Efficiency
- 성능을 아무리 늘려도 결국엔 power 절약을 위해 성능을 줄이게 됨
- power becomes more important --> power를 줄여야한다....
Fallacies & Pitfalls
Pipelining is independent of technology
- Pipeline-related ISA design needs to take account of technology trends
Poor ISA design can make pipelining harder
Concluding Remarks
ISA influences design of datapath and control.
Pipelining improves instrucion throughput using parallelism.
- latency for each instruction not reduced
Hazards : structural, data, control
Multiple issue and dynamic scheduling(ILP)
- Dependencies limit achievable parallelism
- Complexity leads to the power wall
end of chapter 4.
'전공 > 컴퓨터구조' 카테고리의 다른 글
| Memory Hierarchy(4) - virtual memory (0) | 2023.12.28 |
|---|---|
| Memory Hierarchy(3) - Cache_2, Hamming code (0) | 2023.12.28 |
| Memory Hierarchy(2) - Cache_1 (0) | 2023.12.28 |
| Memory Hierarchy(1) - Disk access time (0) | 2023.12.28 |
| Pipelining(1) (1) | 2023.12.28 |

